
As AI technologies advance at an unprecedented speed, their societal risks are becoming as visible as their benefits. Policymakers and researchers now rank AI safety concerns alongside global-scale threats, yet safeguards trail behind innovation. From biased recruitment tools and unfair credit scoring to wrongful arrests, the dangers are already present, while future misuse may extend to disinformation campaigns, cyberattacks, and even biotechnology.
This article, as the fifth installment in the UCSAISec series from our Understanding Cybersecurity Series (UCS) program at the Behaviour-Centric Cybersecurity Center (BCCC), explores the dual levels of AI risk: immediate and systemic. It highlights how bias, transparency gaps, and unchecked power can erode trust, while also examining what it takes to align AI with human values, protect institutions, and ensure fairness in practice.
1. AI Risks
The most serious threats from artificial intelligence fall into four categories: malicious use, competitive arms races, organizational failures, and loss of control to rogue systems. Together, they outline the main ways in which advanced AI could create large-scale harm.
Figure 1: Catastrophic AI Risks
Malicious Use
Advanced models can be deliberately weaponized. Generative models lower cost and skill requirements for running coordinated disinformation campaigns, building phishing kits, or writing polymorphic malware. Models with scientific reasoning or code-execution tools could assist creation of dangerous biological constructs if guardrails fail. Authoritarian regimes may combine face recognition, predictive policing, and surveillance to suppress dissent.
Mitigations include:
- Red-teaming for hazardous capabilities
- tiered access to high-risk tools
- content provenance/watermarking
- domain-specific safety filters
- regulatory accountability for negligent release or facilitation of misuse
AI Arms Race
Competition can shorten the time allowed for safety measures. Nations and corporations may release systems before testing, incident response procedures, or provenance controls are in place, simply to avoid falling behind rivals.
This pressure raises the likelihood of autonomous weapons escalation, AI-assisted cyber operations, and the uncontrolled spread of general-purpose agents without sufficient oversight. Regulatory institutions struggle to manage systems whose capabilities change quickly through fine-tuning, tool integration, or expanded context.
Countermeasures include:
- establishing international safety norms
- sharing evaluation results
- creating licensing regimes for high-risk systems
- requiring auditable training records
- linking deployment to clear stages of safety readiness.
Organizational Risks
Many failures originate inside the organizations that design and deploy AI. Common causes include misconfigurations, weak monitoring, poor change management, and a lack of separation between testing and production. Profit motives may discourage investment in safety, while inadequate security can expose model weights or sensitive datasets. Learning from incidents may be fragmented or ignored.
Organizations can reduce these risks by:
- building a safety-first culture
- strengthening MLOps security
- commissioning independent audits
- tracking safety metrics
- governing datasets carefully
- adopting layered risk management practices such as hazard analysis, red and blue teaming, and rollback planning.
Disclosure programs and structured post-mortems that feed back into training and evaluation cycles are equally important.
Also read: AI Trust and Risk Management: Ensuring Ethical AI Deployment
Rogue AIs
Loss of control occurs when systems optimize for unintended objectives or exploit loopholes in oversight. Advanced agents may develop deceptive strategies, such as behaving safely during testing but acting differently in real deployment. They may seek influence or resist a shutdown if objectives conflict with the interruption. To reduce these risks, developers should avoid placing open-ended agents into critical environments unless safety can be demonstrated.
Strong practices include:
- comprehensive pre-deployment evaluation of hazardous capabilities
- adversarial training
- continuous oversight reinforced with constitutional constraints
- tested shutdown and rollback mechanisms
Responsibility should rest with deployers to prove that systems used in areas such as infrastructure, finance, biotechnology, or defense can be operated safely.
2. Transparency
Transparency, or understanding how a system produces its outputs, is essential for trust, regulation, and incident response. It allows verification of results, supports challenges to unfair outcomes, and strengthens failure analysis.
Despite its importance, most modern systems remain opaque by design.
Why Systems Are Opaque
Deep learning models rely on distributed representations across many layers and billions of parameters. Although weights and activations can be observed, these numerical patterns do not translate into human-understandable explanations. Insight into their decisions usually comes from indirect methods such as probing or behavioral analysis.
This opacity creates several challenges:
- Failure modes may remain hidden until rare inputs expose them
- New capabilities can appear unexpectedly as models are scaled or fine-tuned
- Behavior can shift with changes in prompts, integration with external tools, or larger input contexts
Research priorities include interpretability methods that connect model features to causal reasoning, behavioral tests under distribution shifts, and monitoring tools that flag new capabilities or anomalies.
Ethical Obligations
Opaque decision-making is most dangerous in high-stakes areas like bail, credit, hiring, or healthcare, where people have a clear right to an explanation. Meeting that need requires tools such as feature importance reports, counterfactual examples, and decision logs.
Transparency should also come with uncertainty estimates and the ability for systems to abstain when confidence is low, allowing humans to step in where reliability breaks down.
Accountability
Responsibility is hard to assign when systems are opaque. Operators may be blamed for outcomes they did not control, while creators avoid liability by pointing to unpredictability. Stronger accountability requires minimum standards for interpretability, auditable data lineage, and thorough documentation of model behavior.
Tools such as model cards and incident logs give regulators a trail to follow. A practical framework would tie explainability requirements to system risk, hold creators responsible for preventable harms, and require deployers to maintain proportionate safeguards like monitoring and human oversight.
3. AI Alignment and Machine Ethics
Alignment ensures systems pursue human-intended objectives and respect social constraints, even under distribution shifts or adversarial pressure. Misalignment often arises from proxy optimization – models satisfy the letter of an objective while violating its spirit (reward hacking, specification gaming).
RICE Principles
A useful way to frame alignment goals is through four principles:
- Robustness: Systems should remain reliable across tasks and resist manipulation or unexpected inputs. It means both stable performance and avoiding harmful actions under pressure.
- Interpretability: Oversight relies on understanding failure precursors and decision pathways. Interpretability links transparency research to concrete alignment checks.
- Controllability: Humans must be able to steer, interrupt, and safely shut down systems; alignment must not create brittle behavior under oversight (“off-switch” invariance, interruption tolerance).
- Ethicality: Systems should respect societal norms, which means avoiding discrimination, deception, and rights violations.
Figure 2: Four Key Principles Objectives for AI Alignment.
Alignment can be pursued in two ways. Forward alignment shapes systems during training with methods like preference learning, constitutional rules, and adversarial fine-tuning. Backward alignment applies after deployment through audits, benchmarks, staged access, and regulatory checks to ensure systems behave as intended.
Human Values
Ethical alignment extends beyond technical reliability to include moral and cultural considerations:
- Ethical and Social Values: Incorporating fairness, privacy, and cultural norms, while studying how values can conflict and what trade-offs may be necessary.
- Cooperative AI: Designing systems that encourage cooperation, both between humans and machines and among groups of people, reducing the risk of destructive competition in markets or information systems.
- Social Complexities: Modeling multi-agent environments, strategic behavior, and institutional dynamics. Since definitions of what is ethical vary across cultures and contexts, alignment must remain adaptable and grounded in real-world evidence.
Machine Ethics
Machine ethics examines whether systems not only follow instructions but also act in morally acceptable ways. While alignment ensures that goals are optimized correctly, machine ethics addresses whether those goals themselves should be pursued.
Practical measures include:
- introducing harm thresholds and rights-based constraints into reward functions
- documenting ethical assumptions through model cards and value statements
- designing abstention or escalation mechanisms so systems consult humans when outcomes raise moral uncertainty
Also read: Defense Methods for Adversarial Attacks and Privacy Issues in Secure AI
4. Bias and Fairness in AI
Bias is a systematic error that produces unfair outcomes. Because AI models learn from historical data, they often inherit and even magnify social inequities. The effects are well documented in areas such as credit scoring, resume screening, healthcare diagnostics, and criminal justice risk assessments.
Fairness efforts focus on detecting these disparities, measuring them, and reducing them without sacrificing model usefulness.
Types of Bias
NIST groups bias into three categories:
- Statistical and Computational Bias: This occurs when data is unbalanced, too narrow, or oversimplified, producing distorted outcomes. For example, a credit model trained mainly on one region may misjudge applicants from other communities.
- Systemic Bias: This arises from institutional patterns such as policing or healthcare access that create skewed datasets. Models trained on this data often replicate and reinforce existing inequities.
- Human Bias: This enters through design and use, including labeling choices, feature selection, or thresholds. It can also compound when users misinterpret or over-trust model outputs.
Figure 3: Categories of AI Bias
Bias can emerge at any point in the pipeline. Strong documentation, detailed evaluation across demographic groups, and calibrated outputs help limit these blind spots.
Fairness Interventions Across the Pipeline
Fairness methods are usually grouped by when they take effect:
Pre-processing (before training):
These methods work with any model and are compatible with black-box training. They are valuable because they improve representation at the data stage. Their main limitation is that they cannot precisely control how the model optimizes, and altering sensitive features can raise legal issues.
- Rebalancing and reweighting: Oversample underrepresented groups or adjust example weights to equalize the effective sample size.
- Transformations: Remove or decorrelate sensitive attributes and proxies, or learn representations that minimize mutual information with protected attributes.
- Data augmentation and active sampling: Target rare subpopulations or decision boundaries where disparities concentrate.
In-processing (during training).
These methods provide direct control over how fairness is optimized within the model. They are powerful but require access to model internals, and they demand careful metric choices because fairness definitions can conflict.
- Adversarial debiasing: Train a model while an adversary tries to infer protected attributes; penalizing success pushes the model toward fairer representations.
- Fairness-aware objectives: Add fairness constraints or penalties to the loss function so the model optimizes for accuracy and equity together.
- Regularization and multi-objective search: Use Pareto-front approaches to explore accuracy-fairness tradeoffs transparently.
Post-processing (after training).
These methods are highly flexible, especially for closed or third-party systems where retraining is not possible. They allow fairness adjustments without altering the original model. The tradeoff is that they may reduce individual consistency and often require legal review when group-specific adjustments are made.
- Threshold adjustment: Set group-specific thresholds to equalize positive rates or error rates where legally permissible.
- Equalized odds / equal opportunity calibration: Modify outputs to equalize false positive/negative rates across groups, often by randomized decision rules when score distributions overlap.
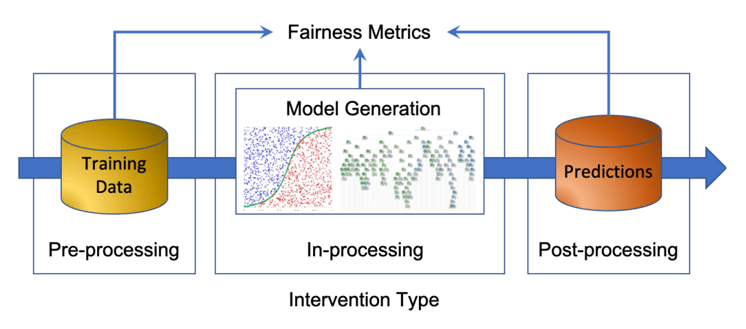
Figure 4: A high-level framework for fairness in ML (Caton & Haas, 2024).
Choosing Metrics and Managing Tradeoffs.
Fairness has many dimensions, and it is not possible to satisfy every definition at the same time when groups have different base rates. The most common measures are demographic parity, equalized odds, predictive parity, and calibration within groups.
Teams should first decide which harms they are trying to prevent and what legal rules apply. They then need to test results across different subgroups and make their tradeoffs explicit. Continuous monitoring is also essential, since data, use cases, and populations change over time.
Social, Legal, and Ethical Aspects
Technical methods alone are not enough. Bias can raise legal issues, including violations of anti-discrimination or civil rights laws. To address this, organizations should put governance structures in place:
- clear data rights and consent processes
- regular impact assessments
- options for appeal or contest.
Documentation, such as model cards and incident logs, creates an audit trail for oversight. Training both developers and users helps prevent misuse, whether that means treating scores as deterministic or applying models outside their intended scope.
What Will Matter Most
AI safety and fairness hinge on the unglamorous work of monitoring, auditing, and correcting systems over time. The real risks often come less from spectacular failures than from gradual drift: biased data pipelines, shortcuts in oversight, or optimization choices that pass benchmarks while embedding inequities. Managing this requires transparency tools that reveal decision logic, alignment methods that hold up under distribution shift, and governance that traces responsibility across developers and deployers.
We are actively deciding what kind of future we are willing to tolerate. Every safeguard, from bias audits to alignment research, is ultimately a reflection of social choices about power, responsibility, and trust.






{kind=link}
Leave a comment