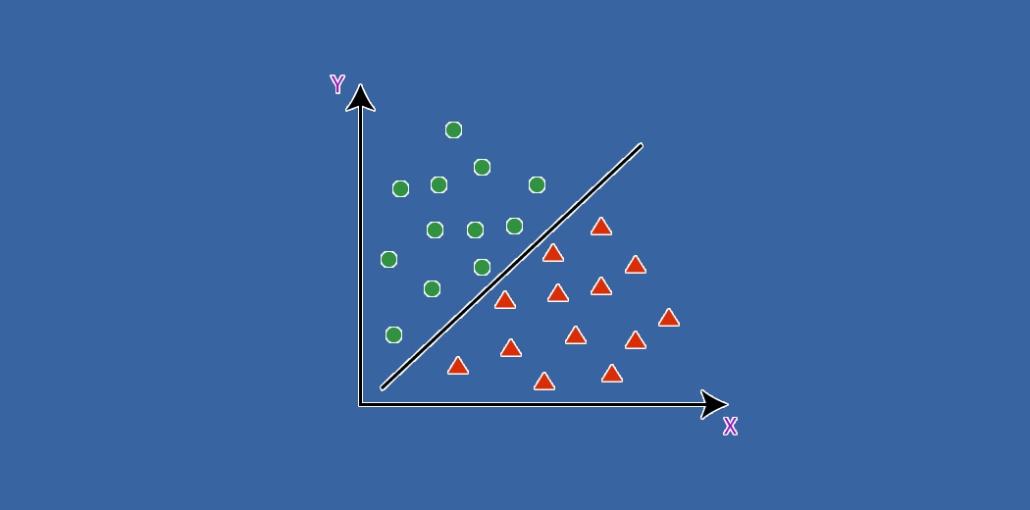
As the name itself says, Classification refers to the assignment of ordering things into various subcategories. But, I know you are shocked thinking how can a machine do so! Just imagine, your laptop recognizing a stranger trying to log in to your laptop and not allowing the immigrant to do so. Or the machine easily identifying a tomato and potato. Adding more cases, the machine grading you from A to F based on your aggregate marks.
No doubt it sounds intriguing at this point! But don’t worry. In this particular blog, we will try to try all the concepts of Classification. The topics to be covered include:
- Formal definition
- A case study
- Getting familiar with the terminologies associated with a classification
- Types of Learners in Classification Technique
- Top 5 classification algorithms which are widely used in Machine learning.
- Summary
Definition
I hope you all have a basic understanding of what Classification means in the language of Computer Science. In Machine Learning and Statistics, the task of classifying various data into subclasses of a given arrangement is what we mean by the term Classification. It can be applied for implementation in both organized and unorganized datasets. The classification method begins with foreseeing the class of the given input data where the classes are regularly alluded to as target, mark or classifications.
We all have heard about supervised and unsupervised Machine Learning techniques. The Classification algorithm belongs to the family of Supervised Learning that has been utilized to recognize the classification of groundbreaking perceptions based on the training dataset. In Classification, a program gains enough information from the given dataset or perceptions, trains itself properly, and afterward builds the model for various classes or gatherings.
For example, True or false, 0 or 1, Have cancer or not, Email is Spam or Not Spam, potato or tomato, and a lot more such types. Classes can be referred to as targets/marks or classification machine learning. In the classification algorithm, ‘y’ which is the discrete output function is mapped to the input variable, ‘x’. The equation is given by: y=f(x), where y is the categorical output.
Also read: How to Machine Learning Startups Are Ushering in a Data Revolution
Exemplar Case
Let us try to understand it much better by comprehending the help of an example case. Suppose we need to recognize the presence of Coronary illness among a mass group of 10,000 people. This is the instance of a binary classification where there can be just two classes i.e has a coronary illness or doesn’t have a coronary illness.
The classifier, for this situation, needs previous data to see which and how the given factors can be identified for the detection of the disease. Furthermore, when the classifier is prepared precisely, it can very well distinguish if the coronary illness is there for a specific patient or not.
Classification is one of the most important concepts about Machine Learning and every beginner should understand the topic till its depth. As it categorizes the set of data into various classes, it can be either binary classification or multiclass classification. Some of the practical applications of classification algorithms involve face detection for protection, speech and iris recognition, document classification, and a lot many.
Terminologies Associated
The various terminologies used with classification in Machine Learning are:
- Classifier – It is a type of machine learning algorithm that is utilized to map or plan the input data to a particular classification depending on its subcategories.
- Characterization Model – The model draws and tries to predict a conclusion to the data information given for the training and testing of the dataset. It will anticipate the appropriate class or classification for the given input data.
- Feature – It is referred to as a component or an individual which is the quantifiable property of the marvel being noticed.
- Binary Classification – It is the type of classification that gives us two results, for instance, either the patient is suffering from heart disease or not.
- Multi-Class Classification – It is the type of classification that has more than two results or outcomes. In multi-class characterization, each example is allocated to one and only one name or target. For ex: Classifying the types of storybooks can be humorous, fiction, horror, emotional.
- Multi-Label Classification – It is the type of classification where each example is relegated to a bunch of marks or targets.
- Initialize – It is used to appoint and utilize the classifier for the model building.
- Train the Classifier – Each classifier in sci-unit learn utilizes the fit(X, y) technique to fit the model for preparing the train X and train mark y.
- Predict the Target – For an unlabeled perception X, the predict(X) strategy returns the anticipated name y.
- Evaluate – This fundamentally implies the assessment of the model i.e accuracy, F1 or bleu score, classification report, and so on.
Learners in Classification technique
There are two kinds of learners in the Classification technique which are divided as lazy learners and eager learners.
So, what are Lazy Learners? Their main purpose is to store the training data and delay until the testing information shows up. At the point when it does, classification is carried out in the stored training information on the most related information. In contrast with eager learners, lazy or languid learners have less preparation time yet get additional time in foreseeing. Some of the examples include Case-based reasoning and K-nearest neighbors.
On the other hand, Eager Learners build a proper classification model dependent on the given training information prior to getting the testing data. It should have the ability to focus on a solitary theory that covers the whole occurrence space. Because of the development of the model, eager learners consume most of the time for training data and less time for predicting the output. Some of the examples include Naive Bayes Classifier, Decision Trees, and Artificial Neural Networks.
Classification Algorithms in Machine Learning
If you want to become an expert in deploying models, then you should study a lot about various Classification algorithms in Machine Learning because the choice of algorithms or techniques completely depends on the available dataset you’re working with. In order to develop business strategies, time series analysis and algorithms for model building are two vital and core components. If you want to grow your career in this vast domain and have some knowledge on how to evaluate, predict and monitor business trends, then check out the article on Time Series Analysis.
It is not possible to discuss all algorithms on one page, so we will discuss the most common ones :
1. Logistic Regression
One of the most popular classification algorithms in Machine Learning is Logistic Regression. In this algorithm, the probabilities depicting the potential results of a solitary preliminary are displayed utilizing a strategic capacity. Scaling of input features and tuning is not needed in logistic regression and it is highly interpretable.
Benefits: Logistic regression is intended for classification primely, and is generally valuable for understanding the impact of a few autonomous factors on a binary result variable.
Drawbacks: Works just when the anticipated variable is paired, expects all indicators are autonomous of one another, and accepts information that is liberated from missing qualities.
2. Random Forest
Random Forest classifier is a meta-assessor that fits various decision trees on different sub-examples of datasets and utilizations normal to work on the prescient exactness of the model and powers over-fitting. The sub-example size is consistently equivalent to the first info test size yet the examples are drawn with substitution.
Benefits: Random Forest Classifier helps to reduce overfitting and is more exact than decision tree algorithm. When implemented in huge datasets, it provides a high level of accuracy and prediction, handling missing data quite efficiently.
Hindrances: Slow ongoing forecast, hard to execute, and complex calculation.
Also read: How Open source machine learning project help to tester with protect security flaws
3. K-Nearest Neighbors
These arrangement based algorithms are a sort of languid learning as it doesn’t endeavor to build an overall inner model, yet basically stores examples of the preparation information. Order is figured from a straightforward greater part vote of the k closest neighbors of each point.
Benefits: This calculation is easy to carry out, strong to boisterous training information, and turns out to be quite successful while dealing with large training datasets.
Inconveniences: The algorithm cost is high and the value of K should be decided well as it needs to register the distance of each case to all the preparation tests.
4. Naive Bayes
This classification algorithm is highly dependent on Bayes’ hypothesis with the presumption of freedom between each pair of highlights. Naive Bayes classifiers function admirably in some certifiable circumstances, for example, spam classification and document classification. Based on Bayes’ theorem, Naive Bayes algorithm is represented as:

Where: P(A | B) represents how often A will occur given that B has occurred, P(A) and P(B) shows how likely A and B will happen respectively and P(B | A) represents how often B will happen given that A has already happened.
Drawbacks: Naive Bayes is known to be an awful assessor.Benefits: This algorithm requires a limited quantity of training information to gauge the important boundaries. Naive Bayes classifiers are amazingly quick contrasted with more modern strategies.
5. Decision Tree
The algorithm which allows us to visually represent our decisions is what we mean by a decision tree. Given information of qualities along with its anything but, a choice tree delivers a grouping of decisions that can be utilized to characterize the information.
Benefits: The decision Tree is easy to comprehend and picture, requires little information readiness and can deal with both mathematical and clear-cut information.
Impediments: Decision trees can make complex trees that don’t sum up well. These trees turn out to be precarious because a slight modification in the training data may bring about a totally different model being produced.
The Summary
Classification in Machine learning utilizes the numerically provable aid of calculations to perform scientific undertakings that would take people many more hours to perform. Also, with the appropriate calculations set up and an appropriately prepared model, classification programs perform at a degree of precision that people would never accomplish.







{kind=link}
Leave a comment