
AI is revolutionizing every industry it touches, but its growing integration into critical systems also opens new security vulnerabilities. As machine learning models become more sophisticated, they attract attackers who aim to exploit their design, data, and functionality.
This article, as the third article of the UCSAISec series, explores the various security threats and vulnerabilities associated with AI systems, especially adversarial attacks that target the integrity and confidentiality of AI models. It also delves into the defensive strategies that can be adopted to mitigate these threats, including privacy-preserving methods like differential privacy and federated learning. By examining attack vectors, attacker capabilities, and mitigation frameworks, we provide a comprehensive understanding of how to build secure and privacy-conscious AI systems capable of resisting evolving cyber threats.
6 Key AI Security Vulnerabilities
AI systems inherit security flaws from both software and data pipelines. Unlike traditional systems, machine learning models are data-driven, which means their behavior is shaped by the quality and structure of training data. This makes them uniquely vulnerable to attacks targeting their inputs, training data, model parameters, and deployment infrastructure.
Training data is the first point of failure. Deep learning models often rely on large datasets, and their quality and diversity directly affect performance. If datasets contain non-robust or misleading features, attackers can exploit them to create adversarial inputs. High-dimensional datasets are particularly problematic, as they may obscure malicious alterations behind statistically irrelevant features. Models trained with insufficient data or data with unbalanced class distributions are even more susceptible to such attacks.
From a model design perspective, linear classifiers and shallow networks are vulnerable to perturbations. Even deep neural networks, while more capable, are not inherently secure. Their sensitivity to slight changes and reliance on non-transparent decision-making make them prime targets.
Poor deployment practices exacerbate these issues. APIs that expose model outputs or confidence scores can be reverse-engineered to reveal sensitive training data or model logic. Without proper authentication, rate limiting, and monitoring, adversaries can perform reconnaissance and launch model extraction attacks. Model update pipelines, if unprotected, offer another attack vector. For example, an attacker might introduce poisoned training samples during a scheduled retraining cycle, subtly modifying the model over time.
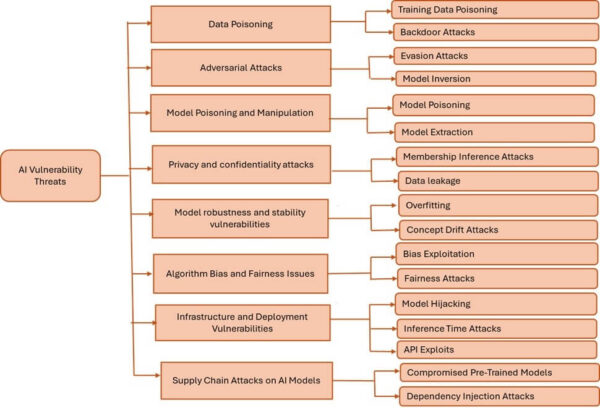
Figure 1: AI Vulnerability Threats Taxonomy
Common vulnerabilities include:
- Adversarial examples: Maliciously crafted inputs that are nearly indistinguishable from legitimate ones but cause the model to produce incorrect outputs. These exploits are especially dangerous in computer vision and natural language models, where even subtle perturbations can lead to misclassifications or unsafe actions.
- Data poisoning: The insertion of manipulated or mislabeled data into the training set to corrupt the model’s learning process. Poisoned data can shift decision boundaries, introduce biases, or embed backdoors.
- Model extraction: Repeated querying of a model to reverse-engineer its architecture, parameters, or decision boundaries. This enables attackers to create functional replicas of proprietary AI systems, undermining IP protection and enabling further attacks like evasion or inversion.
- Membership inference: Techniques that determine whether a specific data point was part of the model’s training set. These attacks exploit overfitting or confidence score disparities to breach user privacy.
- Bias exploitation: Targeting known or learned biases in a model’s training data to trigger discriminatory or skewed outcomes. Attackers can manipulate inputs to bypass detection or gain unfair advantages, especially in systems tied to identity, credit scoring, or hiring.
- Supply chain attacks: Infiltration through compromised third-party AI components, such as open-source libraries, pre-trained models, or data pipelines. These attacks are difficult to trace and may introduce vulnerabilities during the integration or deployment stages
Also read: Understanding AI in Cybersecurity and AI Security: AI in Cybersecurity (UCSAISec-01)
Types of AI Security and Privacy Attacks
Cyberattacks on AI systems can be broadly classified by timing and intent. Training-time attacks undermine learning by feeding malicious data or tampering with model updates. Inference-time attacks focus on triggering incorrect outputs or leaking private information.
- Security-focused AI attacks aim to degrade the integrity or availability of AI services:
- Poisoning attacks insert manipulated data into training sets. This corrupts the model’s logic, resulting in misclassifications or hidden behaviors.
- Backdoor attacks use stealthy triggers to hijack model predictions. For example, an attacker might train a facial recognition system to misidentify anyone wearing a specific sticker.
- Evasion attacks alter input samples just enough to mislead the model at inference time.
- Clean-label attacks trick the model by using carefully crafted—but correctly labeled—data that introduces hidden vulnerabilities.
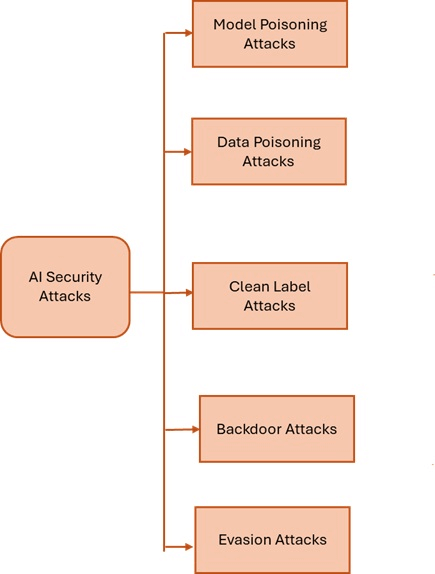
Figure 2: Classification of AI Security Attacks
Privacy-focused AI attacks target confidentiality:
- Model inversion attempts to reconstruct training data by analyzing outputs.
- Membership inference determines if a particular data point was used during training.
- Model extraction clones model behavior via repeated queries.
- Property inference deduces aggregate information from trained models.
- Data leakage occurs when models expose sensitive data through outputs or embeddings.
These attacks pose real-world risks, from data exposure and unauthorized access to financial loss and reputational damage. Understanding them is the first step toward building resilient AI systems.
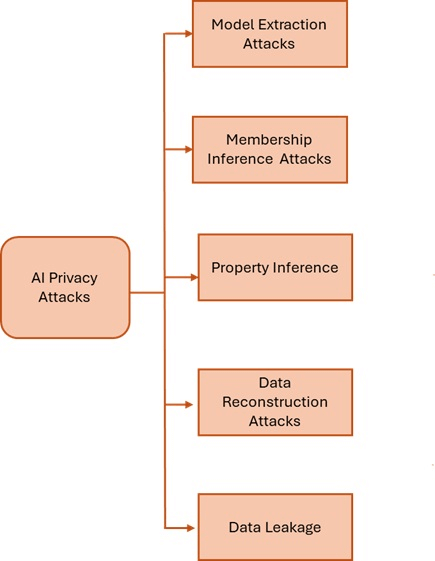
Figure 3: Classification of AI Privacy Attacks
Defending AI Models
To protect AI systems, cybersecurity professionals must implement multi-layered defense strategies. These include algorithmic adjustments, infrastructure protections, and cryptographic techniques.
Adversarial training remains a foundational defense. It involves injecting adversarial examples into the training set, so the model learns to resist subtle input changes. This enhances model robustness and can reduce susceptibility to common evasion attacks.
Differential privacy (DP) introduces noise into gradients or predictions, protecting individual data points from inference. DP is especially effective in settings like health tech or fintech, where data sensitivity is paramount.
Regularization techniques, such as dropout or weight decay, help limit overfitting and reduce the chance of the model memorizing sensitive data. Certified defenses like randomized smoothing and Lipschitz regularization can further bound model sensitivity to perturbations.
Federated learning (FL) reduces risk by decentralizing training. In FL, local devices train models and only share encrypted updates—never raw data. Secure aggregation ensures that no single update is visible to the central server.
Other defensive strategies include:
- Rate limiting and API monitoring to prevent model extraction.
- Input sanitization to reject suspicious queries.
- Explainable AI (XAI) to detect anomalies and monitor behavior.
Combining these techniques offers a defense-in-depth approach to AI security. Each mechanism covers different stages of the model lifecycle, from data ingestion to inference and retraining.
Adversarial Attack Analysis Framework
A comprehensive adversarial threat model provides structure for understanding AI vulnerabilities. The framework begins by defining the AI attack surface, which is the total exposure of a model to potential manipulation. This includes inputs, training data, model internals, interfaces, and outputs.
The attack surface can be conceptualized as a generalized AI data processing pipeline. In the training phase, attackers might poison datasets or alter learning algorithms. They can manipulate inputs or outputs during inference, targeting the model’s decision-making boundaries. Each phase – data ingestion, model training, evaluation, and real-world deployment – presents unique vulnerabilities and must be considered within a layered security framework.
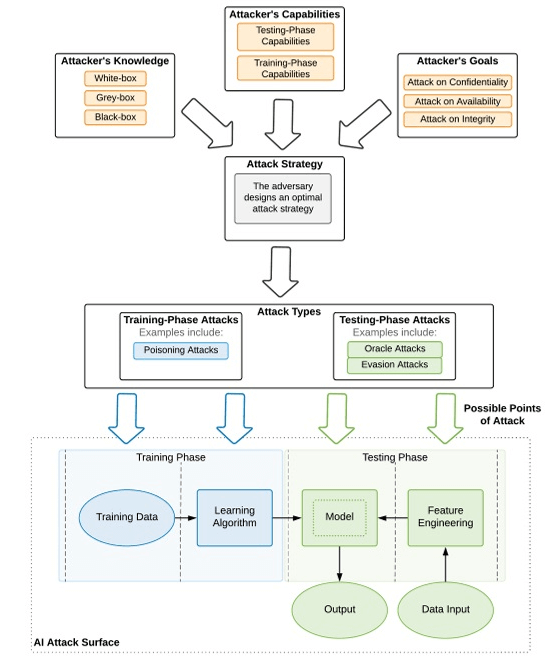
Figure 4: A framework for analyzing adversarial attacks against AI models
(Oseni, et al.; Security and Privacy for Artificial Intelligence: Opportunities and Challenges, arXiv preprint arXiv:2102.04661.)
Attacker Goals
Before designing defenses, it’s critical to understand what attackers want from AI systems. These goals typically mirror the classic cybersecurity triad – confidentiality, integrity, and availability – but manifest in unique ways when applied to machine learning models:
- Confidentiality: Stealing private data or model parameters, such as reconstructing sensitive training examples or learning proprietary algorithms.
- Integrity: Altering model behavior via logic corruption, backdoor injection, or data poisoning, ultimately leading to incorrect or malicious outcomes.
- Availability: Degrading performance through disruption, such as flooding the model with adversarial queries or causing cascading inference failures.
Attacker Knowledge
The feasibility and precision of an attack often depend on how much the adversary knows about the target model. This is typically framed in terms of white-box vs. black-box access, which significantly alters threat modeling.”
- White-box attacks assume the adversary has full knowledge of the model architecture, parameters, training data, and even internal computations, enabling highly targeted strategies like gradient-based input manipulation.
- Black-box attacks operate with no visibility into the model’s internals, relying instead on systematically querying to reverse-engineer behavior. These attacks are harder to prevent and detect due to their exploratory nature.
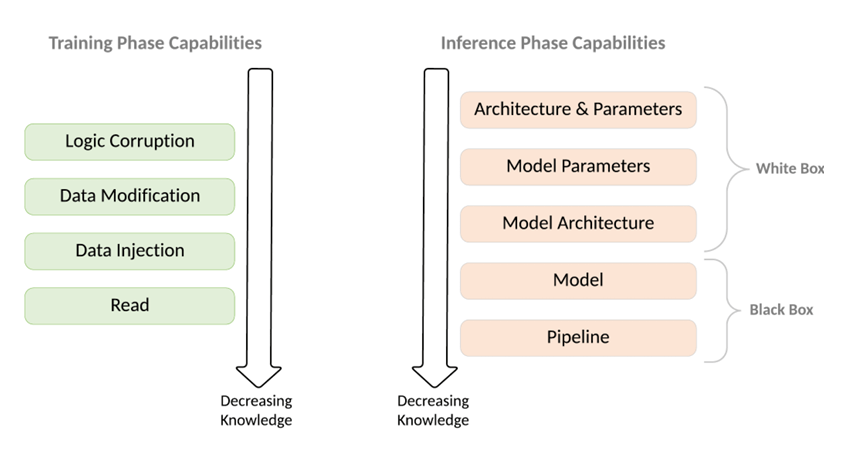
Figure 5: Attacker’s capabilities in the training and inference phases (Oseni, et al., 2021).
Attack Strategies
AI adversaries don’t always attack the same way. Their tactics vary depending on the phase of the machine learning lifecycle they target. A solid defense requires understanding how threats evolve from training to deployment:
- Training-phase attacks, such as data poisoning or label flipping, target the learning process itself, embedding malicious logic from the outset.
- Model-level attacks, including adversarial example generation or bias exploitation, aim to expose or manipulate latent weaknesses in the learned model.
- Inference-phase attacks, such as evasion or model extraction, occur during real-time operation, often combining stealth and automation to bypass defenses.
Adversarial Overlap
Some attacks blur these categories. Hybrid attacks, like clean-label backdoors, begin at training and manifest at inference. Universal adversarial perturbations exploit shared vulnerabilities across inputs or models. Oracle attacks rely on output signals to refine queries and extract logic.
At the heart of these strategies are adversarial examples. These are inputs designed to fool the model while appearing innocuous to humans. They expose flaws in how models generalize from training data and can cross model boundaries due to transferability. Their existence highlights the brittle decision boundaries of many deep learning models and underscores the need for more robust architecture and regularization techniques.
By mapping adversarial goals, capabilities, and techniques to specific stages in the AI pipeline, this framework allows security teams to systematically evaluate risk exposure. Applying it early in the AI development cycle leads to stronger, more resilient architecture.
Also read: Understanding AI in Cybersecurity and AI Security: AI in IoT and OT Security (UCSAISec-02)
Privacy-Preserving AI Methods
Protecting user privacy in AI systems is not optional, especially in regulated industries and consumer-facing applications. Modern approaches combine privacy-by-design architecture with cryptographic safeguards:
Differential privacy mathematically guarantees that no single data point substantially affects model behavior. By injecting statistical noise, DP prevents reidentification and is increasingly used in public datasets, like the U.S. Census and Google Analytics.
Homomorphic encryption allows encrypted data to be used in computations. Predictions are generated without decrypting the inputs, maintaining full data confidentiality throughout the pipeline. Though computationally expensive, it’s suitable for high-stakes cloud applications.
Secure multi-party computation (SMPC) enables collaborative model training without exposing raw data. This technique is widely applicable in healthcare, finance, and cross-border research partnerships where data privacy regulations (e.g., GDPR, HIPAA) restrict sharing.
Federated learning offers a scalable, privacy-first approach by keeping data on edge devices. Apple, Google, and NVIDIA have implemented federated frameworks for applications ranging from keyboard predictions to medical imaging.
Privacy-enhancing technologies are even more powerful when combined. For example, federated learning with differential privacy and secure aggregation protects against both internal leaks and external attacks.
Key benefits of privacy-preserving AI include:
- Reduced regulatory risk.
- Improved user trust.
- Stronger defense against inference attacks.
Building Secure AI Starts at the Foundation
The rise of AI brings new risks, but also new tools for defense. Throughout this guide, we’ve explored how attacks like data poisoning, model inversion, and evasion work, and how defenses like adversarial training, federated learning, and homomorphic encryption help push back. These are part of a broader shift toward responsible AI engineering.
Responsible AI is about trust, reliability, and long-term resilience. And those start with getting the security and privacy foundations right.






{kind=link}
Leave a comment